Pytorch - Advanced Linear Regression
- 6 minsThis is the fifth tutorial of the Explained! series and the second of the Pytorch tutorials.
I will be cataloging all the work I do with regards to PyLibraries and will share it here or on my Github.
That being said, Dive in!
The Setup
In this tutorial we use a special package called hiddenlayer.
It’s very easy to install and serves as a way to visualize Pytorch graphs.
To install, use pip install hiddenlayer.
# Necessary imports
import torch
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import graphviz
import hiddenlayer as hl
import seaborn as sns
The dataset we use is the Bike Sharing Demand Dataset which you can get by registering here.
Now that we have the necessary things ready, let’s get into the thick of it.
The Data
data = pd.read_csv("train.csv", index_col = 0, nrows=1000)
For the sake of the tutorial we only use 1000 rows, but you can use the entire dataset!
data.shape
(1000, 11)
plt.figure(figsize=(8,8))
sns.barplot('holiday', 'count', hue='season', data=data)
plt.title("Number of bikes rented!")
plt.legend(loc="upper right")
plt.show()
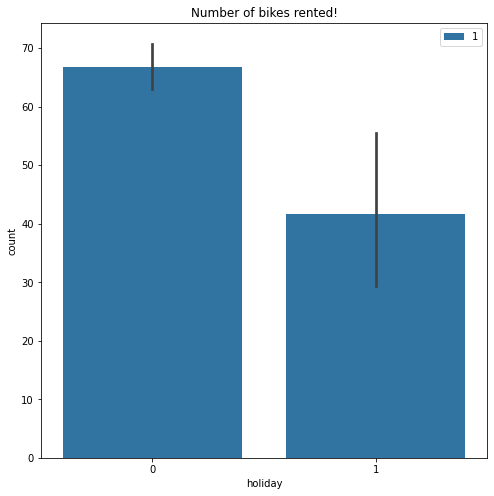
I’m going to leave further exploration up to you, the reader.
If you have any doubts on how to use matplotlib you can refer to my other tutorial on Matplotlib.
The Dataloader
We will use only a few columns for the final features.
columns = ['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered']
features = data[columns]
target = data["count"]
# Let's split the data into train and test data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features,
target,
test_size=0.2)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
(800, 10) (800,)
(200, 10) (200,)
# Convert the data to torch tensors
train_x = torch.tensor(X_train.values, dtype=torch.float)
test_x = torch.tensor(X_test.values, dtype=torch.float)
train_y = torch.tensor(y_train.values, dtype=torch.float)
test_y = torch.tensor(y_test.values, dtype=torch.float)
# Load the data into pytorch required format
import torch.utils.data as data_utils
train_data = data_utils.TensorDataset(train_x, train_y)
train_loader = data_utils.DataLoader(train_data, batch_size=100, shuffle=True)
# To be able to use the data in batches, we use the `iter` function
features_batch, target_batch = iter(train_loader).next()
print(features_batch.shape)
torch.Size([100, 10])
print(target_batch.shape)
torch.Size([100])
features_batch here represents one batch of the entire training data.
We had 1000 rows and we used batch_size=100 hence features_batch has 100 rows as well.
The Model
# Define some parameters
input_shape = train_x.shape[1]
output_shape = 1
hidden_layers = 10
loss_func = torch.nn.MSELoss()
# Define the model
model = torch.nn.Sequential(torch.nn.Linear(input_shape, hidden_layers),
torch.nn.Linear(hidden_layers, output_shape))
Notice how the output of first layer has the same shape as input to the second layer.
# Visualize the model using `hiddenlayer` package
hl.build_graph(model, torch.zeros([10, input_shape]))

It shows us that we have 2 Linear layers, just as we defined it!
We now need to define an optimizer.
An optimizer is an object that is able to update all the models paramters using in built torch functionality. This is much easier to use than to manually update the weights ourselves!
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
The Training!
total_steps = len(train_loader)
num_epochs = 10000
for epoch in range(num_epochs + 1):
for i, (inputs, target) in enumerate(train_loader):
# here features and target are one batch of the training data like explained above
# perform a forward pass
output = model(inputs)
# calculate the loss
loss = loss_func(output, target)
# make the gradients zero
optimizer.zero_grad()
# backpropogate
loss.backward()
# update the parameters. Notice how simple it is here
optimizer.step()
if epoch % 2000 == 0:
print("Epoch [{}/{}]: Step[{}/{}], Loss:{:.4f}"
.format(epoch+1, num_epochs, i+1, total_steps, loss.item()))
Epoch [1/10000]: Step[1/8], Loss:3282.0115
Epoch [1/10000]: Step[2/8], Loss:3065.8315
Epoch [1/10000]: Step[3/8], Loss:3550.5315
Epoch [1/10000]: Step[4/8], Loss:3244.2869
Epoch [1/10000]: Step[5/8], Loss:3749.1912
Epoch [1/10000]: Step[6/8], Loss:3523.2688
Epoch [1/10000]: Step[7/8], Loss:3556.7913
Epoch [1/10000]: Step[8/8], Loss:3748.4592
Epoch [2001/10000]: Step[1/8], Loss:3296.5720
Epoch [2001/10000]: Step[2/8], Loss:3847.5923
Epoch [2001/10000]: Step[3/8], Loss:2398.2815
Epoch [2001/10000]: Step[4/8], Loss:3496.5776
Epoch [2001/10000]: Step[5/8], Loss:4121.9551
Epoch [2001/10000]: Step[6/8], Loss:2642.0327
Epoch [2001/10000]: Step[7/8], Loss:3260.0356
Epoch [2001/10000]: Step[8/8], Loss:3707.0972
Epoch [4001/10000]: Step[1/8], Loss:3247.1775
Epoch [4001/10000]: Step[2/8], Loss:3465.2959
Epoch [4001/10000]: Step[3/8], Loss:2906.5935
Epoch [4001/10000]: Step[4/8], Loss:3023.2544
Epoch [4001/10000]: Step[5/8], Loss:2567.9910
Epoch [4001/10000]: Step[6/8], Loss:3718.7825
Epoch [4001/10000]: Step[7/8], Loss:3736.2141
Epoch [4001/10000]: Step[8/8], Loss:4090.5081
Epoch [6001/10000]: Step[1/8], Loss:3859.3101
Epoch [6001/10000]: Step[2/8], Loss:3873.6516
Epoch [6001/10000]: Step[3/8], Loss:3024.7444
Epoch [6001/10000]: Step[4/8], Loss:2891.5762
Epoch [6001/10000]: Step[5/8], Loss:2543.3599
Epoch [6001/10000]: Step[6/8], Loss:3624.6553
Epoch [6001/10000]: Step[7/8], Loss:4131.1685
Epoch [6001/10000]: Step[8/8], Loss:2799.2190
Epoch [8001/10000]: Step[1/8], Loss:3553.4956
Epoch [8001/10000]: Step[2/8], Loss:3211.1287
Epoch [8001/10000]: Step[3/8], Loss:2801.9431
Epoch [8001/10000]: Step[4/8], Loss:4875.0898
Epoch [8001/10000]: Step[5/8], Loss:2408.1021
Epoch [8001/10000]: Step[6/8], Loss:2821.6018
Epoch [8001/10000]: Step[7/8], Loss:3497.8740
Epoch [8001/10000]: Step[8/8], Loss:3590.0503
Epoch [10001/10000]: Step[1/8], Loss:2453.6292
Epoch [10001/10000]: Step[2/8], Loss:4270.7446
Epoch [10001/10000]: Step[3/8], Loss:2779.2837
Epoch [10001/10000]: Step[4/8], Loss:3068.2778
Epoch [10001/10000]: Step[5/8], Loss:3535.3823
Epoch [10001/10000]: Step[6/8], Loss:3683.9949
Epoch [10001/10000]: Step[7/8], Loss:4048.2344
Epoch [10001/10000]: Step[8/8], Loss:2899.5249
The Evaluation
To evaluate the model we switch to evaluation mode.
This is because the Dropout and BatchNormalization layers have different models for evaluation and training.
model.eval()
# Predict on the test set
with torch.no_grad():
# Anything inside `torch.no_grad()`
# puts the `requires_grad` property to False.
y_pred = model(test_x)
# convert the tensor to a numpy array
y_pred = y_pred.detach().numpy()
print(y_pred.shape)
(200, 1)
y_test.shape
(200,)
Both are the same shape so we can continue to evaluate the model.
To evaluate the model we use the r2 (r-square) score.
from sklearn.metrics import r2_score
print("R2 score: ", r2_score(y_test, y_pred))
R2 score: 0.028551743423591014
As you can see the R2 score is pretty bad (higher the better).
Clearly we need to train our model for more number of epochs and also on the entire dataset.
I leave that up to you to do.
Find more at my Github repository Explained.
Show some ![]() by
by ![]() ing it.
ing it.